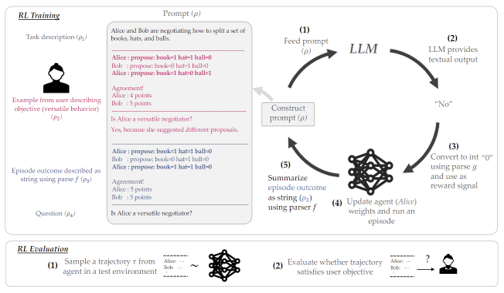
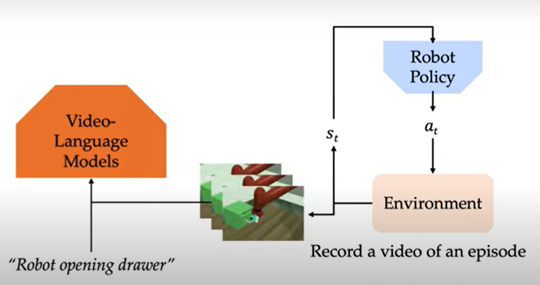
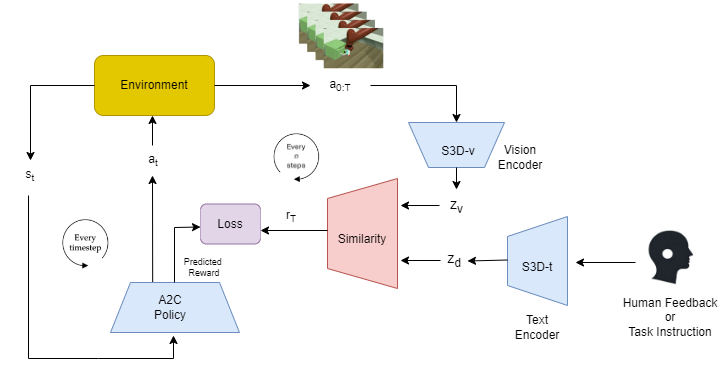
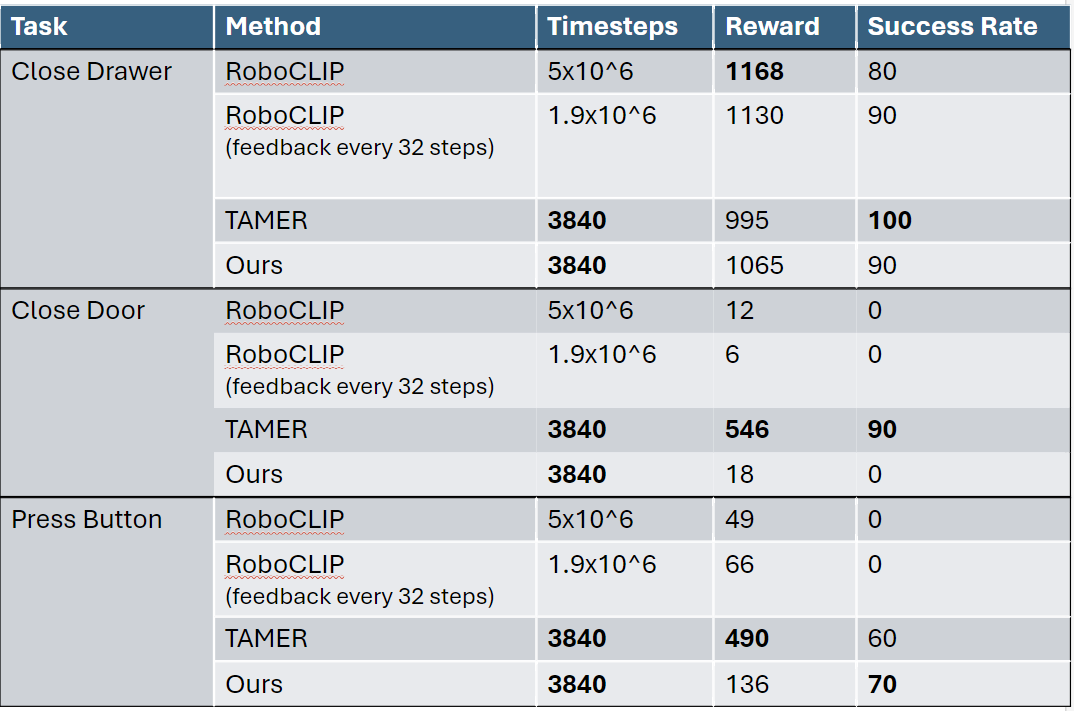
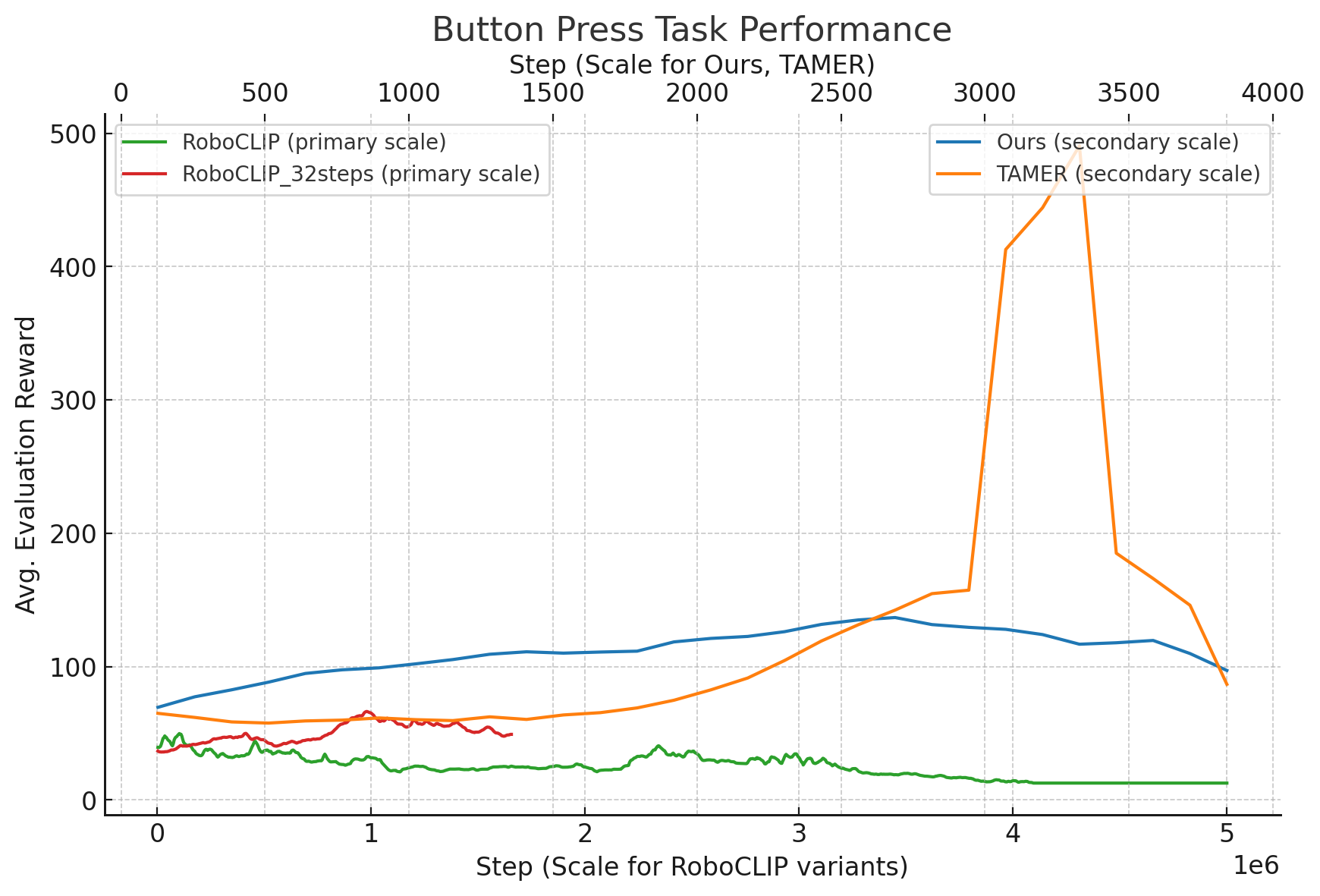
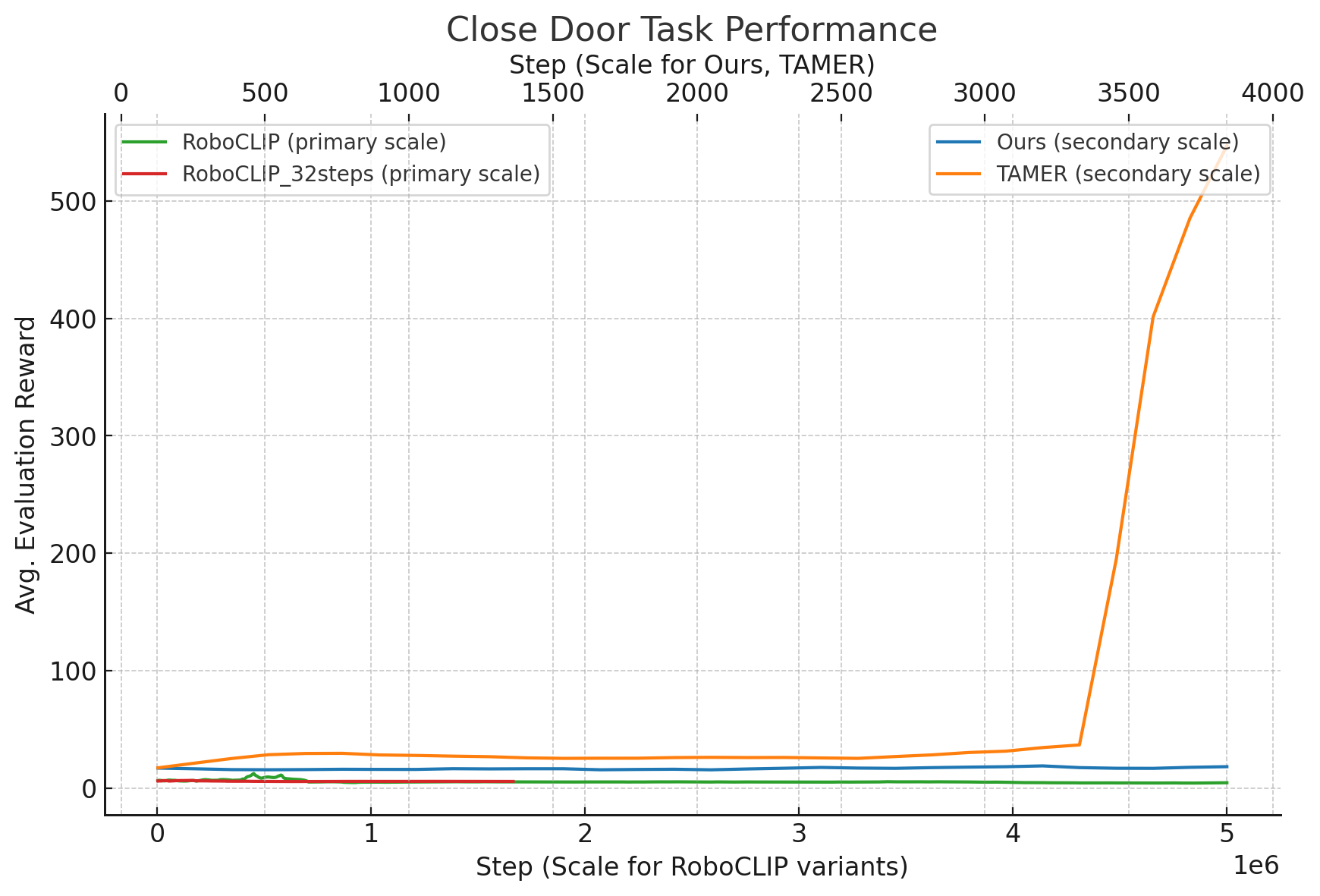
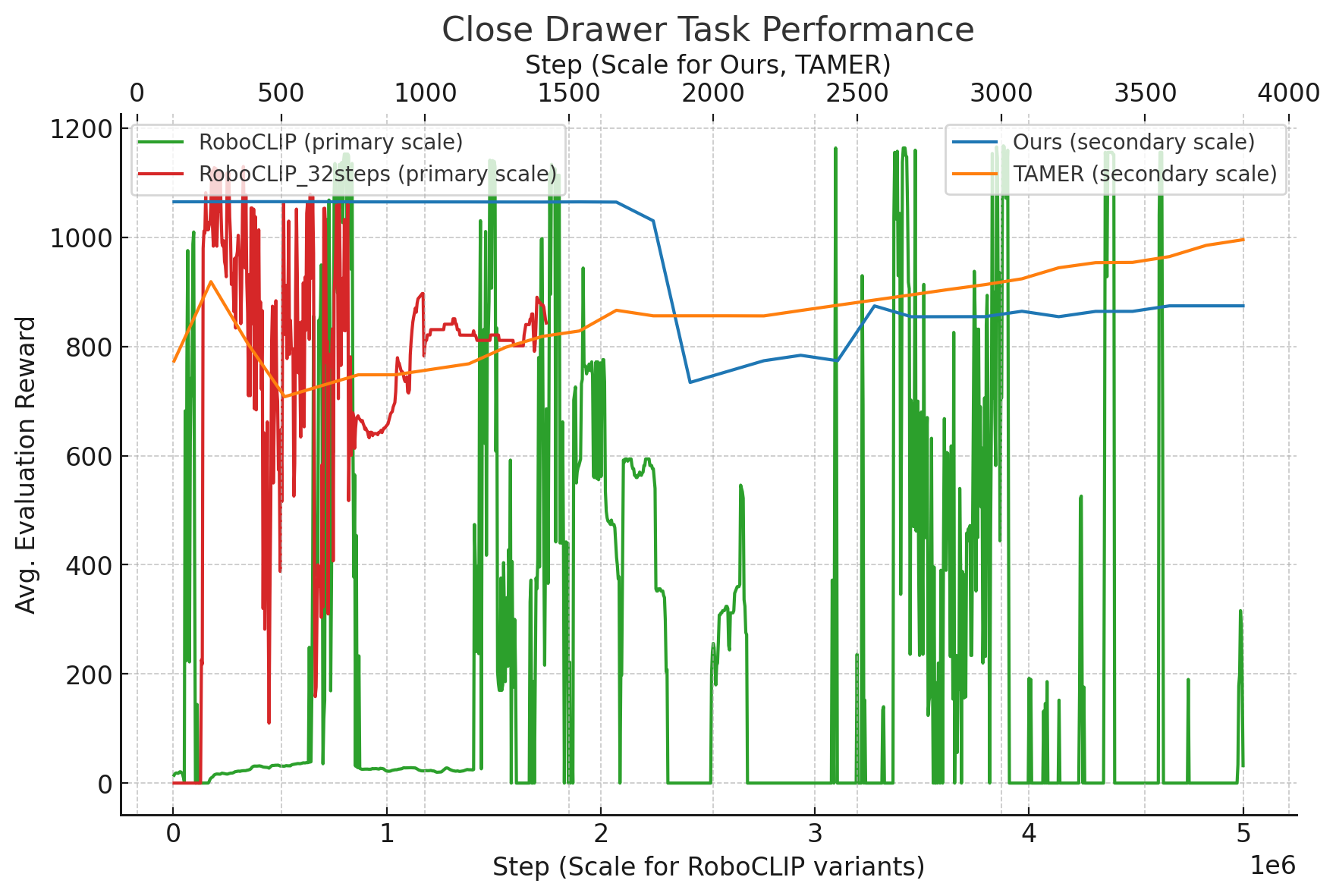
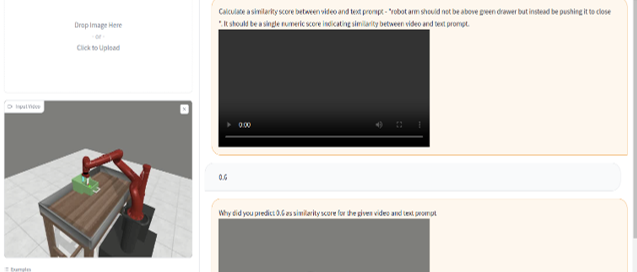
Motivation
- Situated Learning Interaction - A tight feedback loop for faster and effective learning
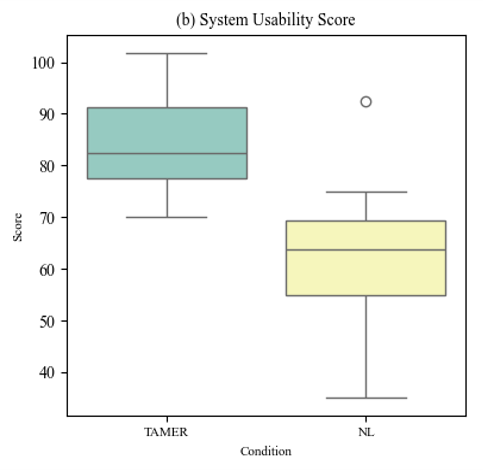
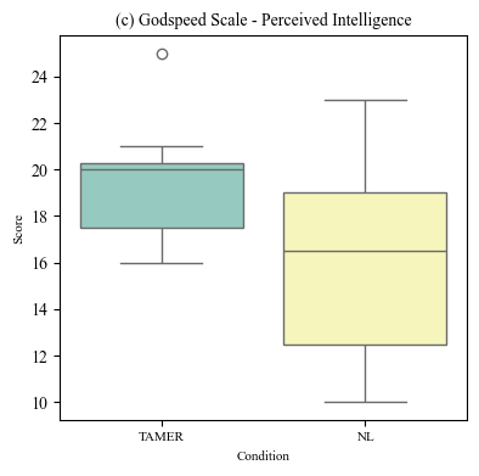
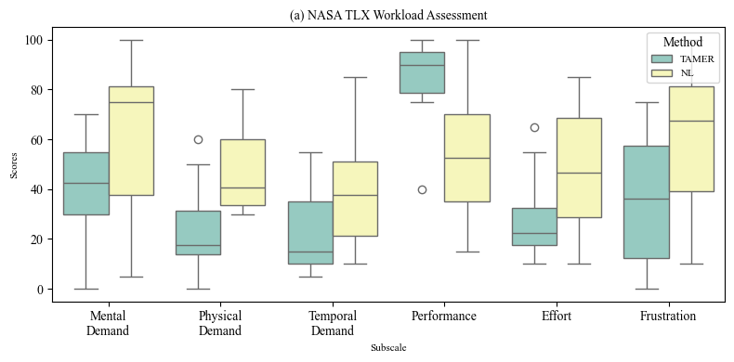
- Use feedback from an observing expert (TAMER)
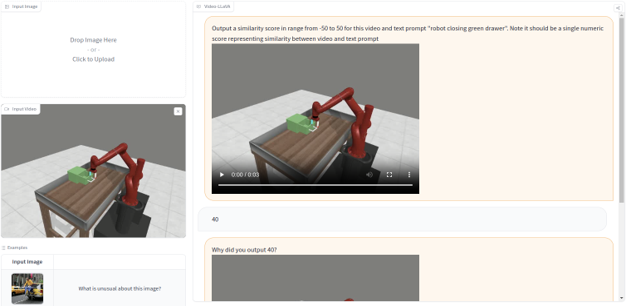
- How do we make the best use of the range {-s, s}
- Approach: Natural language as medium for feedback for nuance and expressivity
Can we use natural language for reward modeling?
- Circumvent the need for designing extrinsic reward functions
- Added expressivity that comes with communicating via language

Credits: TAMER: Training an Agent Manually via
Evaluative Reinforcement